As a web scraper, ParseHub has its own Select tool to choose the elements that you would like to scrape from the website. You can simply click on each element on the page to select and extract.
In some cases, your target element is not visible on the page, and you might want to consider an alternative way to select elements on the page.
This is an advanced tutorial! Before reading this, it's best to have some more familiarity with ParseHub, especially with the Select tool. In your first project you definitely shouldn't need to use XPath selectors.
What does XPath do? How does it work?
XPath is a language that lets you select particular HTML elements from a page that ParseHub is on.
This can be more powerful or precise than ParseHub's default way of selecting elements (by clicking on them), but also requires some more coding knowledge.
If you want to learn some general XPath on your own, there's many tutorials available here.
Why should I use XPath?
In most cases, you shouldn't need to! However, there are a few cases where it might be necessary (or at least a lot more elegant) to use an XPath selection. This includes when...
- you can't select a Next button
- a Next button stays selected on the last page and results in the project never ending
- you need data, such as latitutde and longitude, from a map where it isn't readily available
- hidden elements or previous data are being selected
- different pages on an eCommerce website have different page layouts
How to enable XPath selection
To use XPath to select an element, you have to edit the options of a pre-existing Select or Relative Select command.
1. Click on the Select or Relative Select in the list of commands in your project to select it as the active command.
2. Click on the green Edit button beside Selection Node.
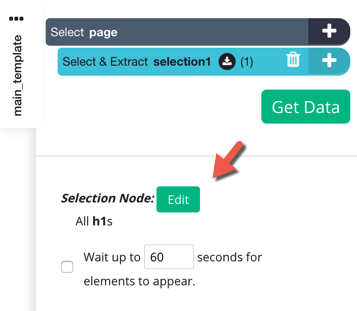
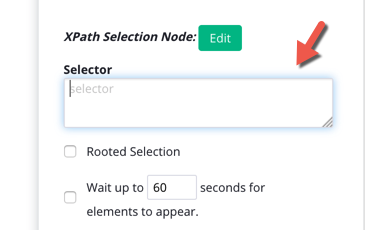
3. Click on Use XPath Selection, which should cause the Selector text box to appear.

4. This textbox is where you can input an XPath path to select elements on the page.
Can you enable XPath with a Relative Select?
Yes, however, the command will no longer be relative. XPath selectors are always select from the entire page.
Rooted Selection
When you use XPath you’ll see a “Rooted Selection” checkbox appear below. Rooted Selection refers to treating the selection as relative to the top of the document rather than to the nearest parent selection.
If enabled, it will select every element on the page instead of within the container that you are currently in.
How to Write in XPath
To use XPath, you need to understand some of the basics of HTML first. XPath selects elements based off of the tags and the attributes of those tags on the page. You can see some simple page layouts here.
You might have noticed that ParseHub already tells you what tags any given selection is using.
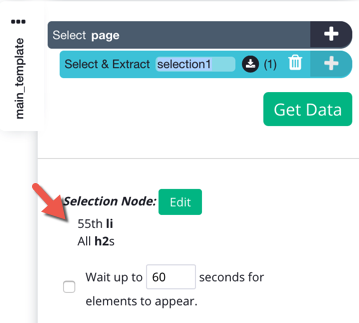
This a refers to a link on the page, in an HTML <a> tag. The link itself is contained in the href attribute.

You might have already noticed the href attribute mentioned if you use an Extract command on a selected link.
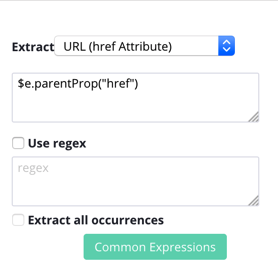
XPath, however, doesn't extract elements, it only selects them.
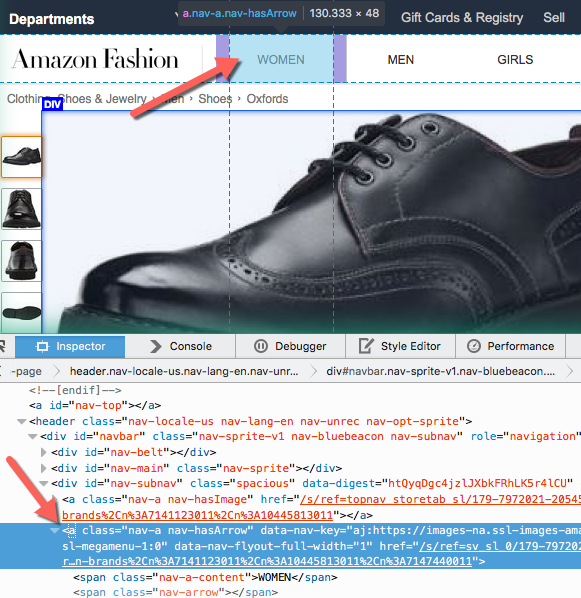
Viewing a Page's HTML
On any page, you can right click and choose Inspect Element in ParseHub to view the HTML layout of the page. This is important to do, so that we can design XPath to pick out the element we want.
Right clicking on the particular element, if you can find it, and inspecting that element will take you to its tag's location in the HTML.
If you hover over tags in the HTML view, the page will highlight the element that your cursor is hovering over.
The Language of XPath
This tutorial is going to just go into the basis of XPath, with the use it has in ParseHub in mind. Of course, there are many many more uses and features in XPath that you can look into and use in ParseHub.
Selecting all elements
To select all tags of one type, use: //tag
You should avoid typing this in for div or span tags, because it can select very many elements and cause ParseHub to crashed. You should write your predicate first, something we'll learn about later.
For example, to select all the links on the page, use //a
Selecting all children
HTML elements are nested, as you can see:
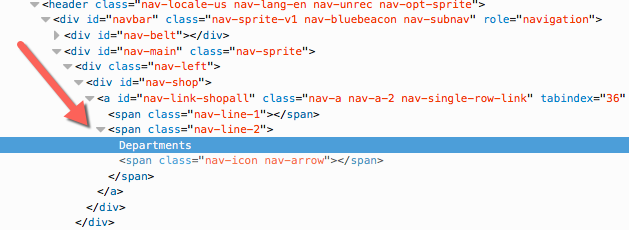
Sometimes, selecting every single kind of element isn't what we want to do because we might only want links (a tags) that are in a particular section (a div tag, here).
We can write this: //div//a
This translate to: "Select all a tags that are somewhere nested underneath a table tag." You can see here what would be selected, and what wouldn't be:

In red are the selected elements. Bolded is the first div that XPath recognizes they are nested under.
Filtering elements based on attributes
We can use predicate tags to narrow down our selection even further. For instance, we might only want to get all links that have a class attribute. We can write this:
//a[@class]
The @ followed by text specifies an attribute of the tag being selected.
But, plenty of a tags have class attributes, what differentiates them is what the class attribute actually is! To do this, we can write:
//a[@class='anythingYouLike']
This is a big jump, because it can really let us pick out one element at a time, as long as each tag has a unique class. When this isn't the case, you might have to look at another attribute, such as @id, or whatever else seems to distinguish it from other tags in the HTML.
Sometimes, writing the exact phrase of the attribute can be slow and bulky. We can instead use contains
//a[contains(@class,'anythingY')] will select all a tags that contain the phrase 'anythingY' in their class attribute, which gets us effectively the same thing as our previous selection. This can help, however, if tags have slightly different classes but share one particular part.
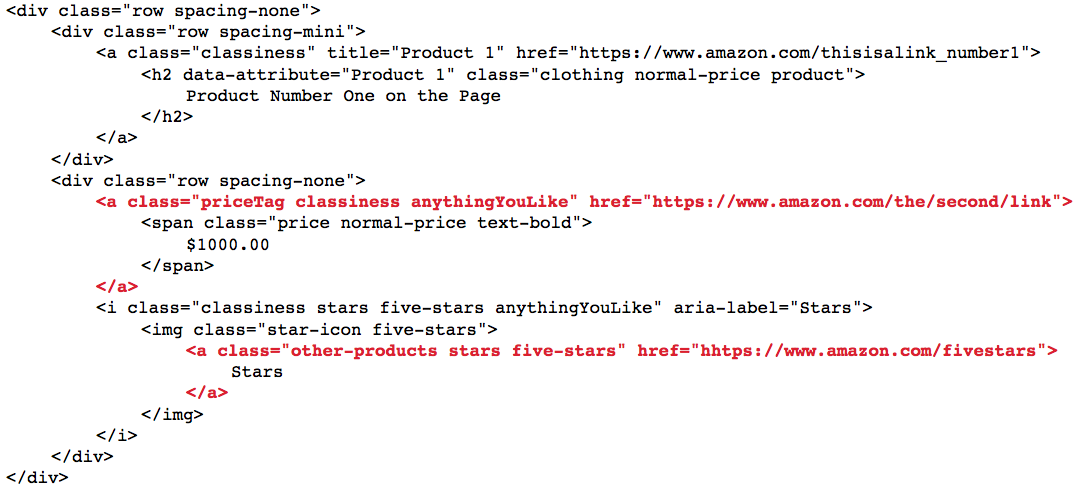 Filtering elements based on HTML structure
Filtering elements based on HTML structure
Sometimes, we only need to select the first, second, or third element on page. We can use a number in predicate tags to specify which child, of the parent tag, to select. To select every 2nd link, we can write:
//a[2]
We can also combine this with our other predicates!
//img[contains(@class,'anythingY')][1] will select the every image on the page which has the 'active' class first, under it's parent.
Keep in mind that this [#] predicate is based on the parent, not the position on the entire page. In a layout like this:
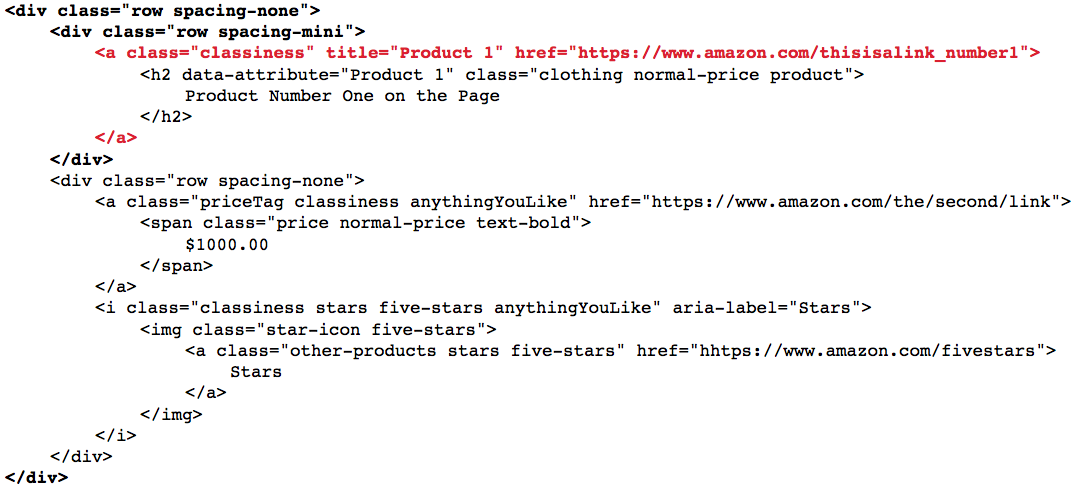
//a[1] won't select the first link overall, but every link that comes first under it's parent tag. You have to select the parents first, then use a [#] predicate tag, then select all first children.
//div[@class='row spacing-none']/div[1]//a[1] is the XPath you need to select the first a tag link on the whole page.
Selecting elements by immediate children
We've been using a double slash so far, because the single slash / has a special feature in XPath. It will only select children exactly one level down.
In the code below, //div[2]/a will select only the highlighted immediate child of the second div tag, but none of the a tags further down.

You can, of course, combine predicates with these single slashes to get very specific selections with XPath.
//div[contains(@class,'spacing-nde')]/div[2]//img[contains(@class,'five-stars')]/a[1] gets only the highlighted in the code below.

When the Tag Doesn't Matter
Sometimes you just need to select an element based on the predicate, and not the tag. This can come up if you need several tags of different types. You can use the symbol * instead of a tag to specific any element
//*[contains(@class,'other-products')] will select the highlighted:

Other times you'll want to check against the text actually shown by the tag. For this, you can use text(), such as in //*[contains(text(),'Next Page')]
Logical Operators
Finally, you can write and and or between predicates within square brackets if you need to specific some even more specific tags.
//a[@aria-label='Stars' and contains(@class,'five')]
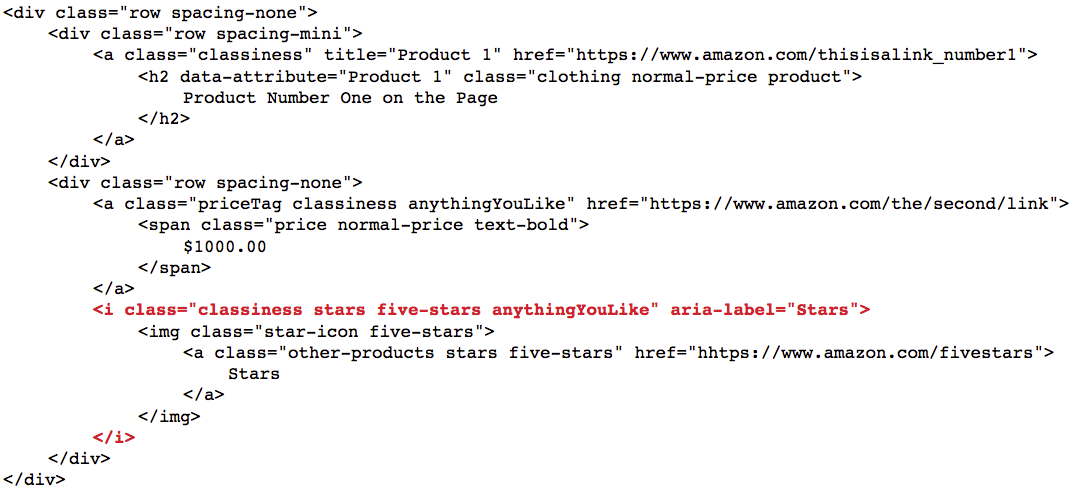
You can also use not() in a predicate to rule out elements.
//div[not(contains(@class,'none'))]

Final Tips
Good job on getting through all of this technical stuff! At the end of the day, using XPath with ParseHub takes practice, and trial and error.
If you need help, you can always Contact Us and our help team will get back to you as soon as possible!